左值-右值-将亡值
最初概念
如何确定一个值是左值还是右值?
通常有一个比较简单的判断方案:有地址的值被称为左值,没有地址的值称为右值
但是事实好像并非如此,特别是写了一些相关代码的时候,比如下面的这段
1 | |
对应的输出结果也写在每一行的后面了,这似乎有一些意料之外的情况
- 第一行,一个单独的数字
1,很明显的确实是一个右值,符合预期 - 第二行,变量
a明显也是一个合情合理的左值,那么也是符合预期的 - 接下来第三行,变量
b作为a的一个引用,那毫无意义也是一个左值(b只是引用了a的值,实际上仍然是a本身),符合预期 - 但是第四行,却让人摸不着头脑,明明
c是一个明确的右值引用,为什么也是一个1
这似乎表明了,c 是一个合法的左值,而非右值
尝试做一些看起来非法的操作
1 | |
看起来非常的合法合理,就像是一个活灵活现的左值,而并非它类型那样描述的右值。即然是左值,那么必然有地址,输出看看
1 | |
从上面的数字可以看出来,c 确实是在栈上,即拥有一个合理合法的地址,这是发生了什么?
调查
如果把上述的代码改成汇编语言后,再看看结果
- 汇编前
1 | |
- 汇编结果(仅摘录核心段)
1 | |
可以注意到,对于引用而言,汇编仍然使用的是指针来解决,所以可以看到变量 b 记录下的是 a 的指针,而非真正的给 a 做了一个别名。而 c 也是一个指针,指向了一个未知的变量。这似乎就是我们寻找的答案
从内存本身而言,任何值都可以认为是左值,因为一个值存在,则必定存在具体的地址,即使它是作为常量的方式写在代码中,那起码它也应该存在于代码段,“存在即有地址”
但是对于这种在代码段“有地址”的值,又违背了代码段不可修改的原则,而具体操作的时候又未免会使用到这些值,这个时候,编译器会将代码段的这个值拷贝到栈空间,然后将其再赋给具体的对象,这个拷贝过来的值,像是一个右值,同时又具有着左值的特点,更确切的说,它属于“将亡值(xvalue)”。
将亡值
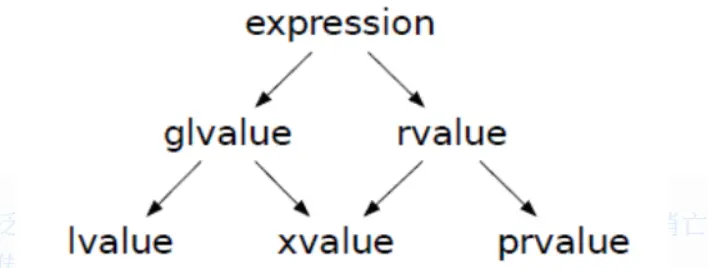
其中,lvalue 和 rvalue 就是我们一般认为上的左值和右值,而 glvalue 则是包含了将亡值的泛左值,而 prvalue 则是指那些纯右值,也就是那些在代码段里的值
将亡值则表示一种中间变量,例如使用了纯右值的时候,或者隐式类型转化,或者函数的返回值,这些都是将亡值充当的角色。实际上他们都有确切的栈上地址。
但是将亡值本身的含义是一个临时存在的变量,终是不可久留,这也就意味着编译器通常会限制对将亡值进行左值引用的方式。例如
1 | |
此时编译器的报错是:Non-const lvalue reference to type 'double' cannot bind to a temporary of type 'double',即无法通过一个非常量的左值引用指向一个将亡值。而当你改成 const double &x = (double)1; 后,程序又可以通过编译了。这也说明了编译器实际上只是在做一些安全性的检查,并没有真正限制修改将亡值,甚至可以将将亡值变成长期存在的栈上的值(例如一开始的程序)